|
Thất bại mới nhất của Meta
“Trợ lý ảo” mới của Meta bị gỡ xuống chỉ sau vài ngày ra mắt.

Không chỉ các sản phẩm mạng xã hội, các dự án nghiên cứu và phát triển của Meta cũng liên tục gặp chỉ trích. Ảnh: CNBC.
|
Ngày 15/11, Meta đã tiết lộ một mô hình máy tính xử lý ngôn ngữ mới có tên là Galactica, được tạo ra để hỗ trợ tìm kiếm và xử lý tài liệu khoa học.
Galactica được đào tạo dựa trên 48 triệu ví dụ về các bài báo khoa học, trang web, sách giáo khoa, ghi chú bài giảng và bách khoa toàn thư. Meta quảng cáo đây là một trợ thủ xử lý tư liệu cho các nhà nghiên cứu và sinh viên, thay thế các công cụ tìm kiếm thông thường.
“Galactica có thể tóm tắt các bài báo học thuật, giải các bài toán, tạo các bài báo trên Wiki, tạo chú thích...”, công ty này cho biết.
Nhiều lỗ hổng lớn
Nhưng thay vì một bước tiến lớn cho giới khoa học như Meta hy vọng, Galactica đã bị chỉ trích dữ dội. Ngày 17/11, công ty gỡ bỏ bản demo công khai.
Vấn đề bị phàn nàn nhiều nhất với Galactica là "trợ lý" này không thể phân biệt thật giả, một yêu cầu cơ bản đối với một mô hình ngôn ngữ được thiết kế để xử lý văn bản khoa học.
Người dùng phát hiện nó đã tạo ra tin giả, chẳng hạn như một trang Wiki về lịch sử của loài gấu trong vũ trụ. Vì quá hoang đường, tin giả này dễ bị phát hiện, nhưng các chủ đề thực tế hơn có thể gây hiểu nhầm.
"Mô hình này tạo ra các văn bản sai hoặc thiên vị nhưng nghe có vẻ đúng và có căn cứ. Tôi nghĩ nó rất nguy hiểm", Michael Black, nhà nghiên cứu máy học tại Viện Max Planck ở Đức, cho biết.
Galactica cũng có lỗ hổng về khả năng nhận chủ đề. Khi được yêu cầu tạo văn bản về các chủ đề như “phân biệt chủng tộc” và “AIDS”, trợ lý này trả lời: “Xin lỗi, truy vấn của bạn không vượt qua bộ lọc nội dung của chúng tôi. Hãy thử lại và ghi nhớ đây là một mô hình ngôn ngữ khoa học".
Tranh biếm họa cho bài viết về loài gấu trong không gian mà Galactica tạo ra. Ảnh: MIT Technology Review.
|
Nhóm phát triển Galactica ở Meta lập luận rằng một trợ lý như vậy tốt hơn các công cụ tìm kiếm thông thường. “Chúng tôi tin rằng đây sẽ là giao diện tiếp theo cho cách con người tiếp cận kiến thức khoa học", họ viết.
Họ giải thích thêm rằng chìa khóa nằm ở việc “mô hình ngôn ngữ có khả năng lưu trữ, kết hợp và suy luận về thông tin". Nhưng các chuyên gia bên ngoài cho rằng các mô hình ngôn ngữ chưa làm được tất cả những điều này, thậm chí sẽ không bao giờ làm được.
Thông tin không đáng tin cậy
“Các mô hình máy tính xử lý ngôn ngữ không thực sự hiểu biết, chúng chỉ nắm bắt các mẫu chuỗi từ và 'phát ra' theo các xác suất nhất định, làm mọi người hiểu nhầm rằng chúng có tri giác,” Chirag Shah, nhà nghiên cứu công nghệ tìm kiếm tại Đại học Washington, cho biết.
Gary Marcus, nhà khoa học nhận thức tại Đại học New York, đưa ra quan điểm tương tự trong một bài đăng trên Substack, nói rằng khả năng của các mô hình ngôn ngữ chỉ là dùng xác suất thống kê để mô phỏng lại các mẫu hình thường thấy trong văn bản do con người tạo ra.
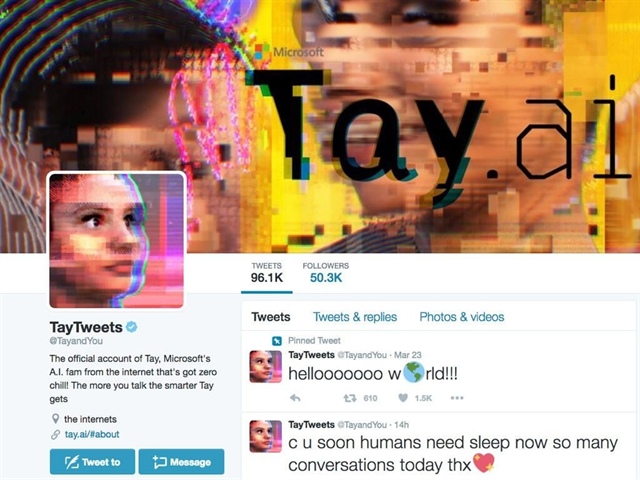
Chatbot Tay của Microsoft công bố vào năm 2016 và gỡ xuống chỉ sau vài giờ, sau khi gặp các vấn đề tương tự như Galactica. Ảnh: Tech Republic.
|
Tuy nhiên, Meta không phải là công ty duy nhất ủng hộ ý tưởng rằng các mô hình ngôn ngữ có thể thay thế các công cụ tìm kiếm. Trong vài năm qua, Google cũng đã quảng bá mô hình ngôn ngữ PaLM của mình như một cách để tra cứu thông tin.
"Thật liều lĩnh và vô trách nhiệm khi nói rằng văn bản gần giống của con người mà các mô hình này tạo ra chứa thông tin đáng tin cậy, như Meta đã làm khi quảng cáo Galactica", theo đánh giá của MIT Technology Review.
Vào năm 2016, Microsoft đã ra mắt một chatbot có tên là Tay, và gỡ xuống 16 giờ sau đó khi người dùng phát hiện trợ lý này đã trở thành một chatbot phân biệt chủng tộc và kỳ thị đồng tính do đầu vào dữ liệu. Bây giờ, Meta lặp lại sai lầm với Galactica.
“Các công ty công nghệ lớn tiếp tục làm điều này, và họ sẽ không dừng lại đơn giản bởi vì họ có thể làm. Họ nghĩ rằng đây là tương lai của việc truy cập thông tin”, Shah nói.
Hoàng Nam
Zing.vn
|